文章目录
- 安装
- Linux/UNIX:
- macOS:
- Windows (非 Cygwin/MSYS):
- 使用 VCPKG 依赖管理器:
- 注意:
- Cygwin/MSYS:
- 使用
- 错误处理
- 函数类型
- 错误处理
- 用户自定义错误处理函数
- 使用用户自定义错误处理函数
- C语言中的错误处理
- C++中的错误处理
- 其他编程语言
- 错误代码列表
- 总结
- 图像
- 图形模式
- 路径绘画
- 路径绘制
- 图形状态操作符列表
- 颜色操作符列表
- 路径构造操作符列表
- 路径绘制操作符列表
- 总结
- 文本显示
- 文本状态操作符列表
- 文本定位操作符列表
- 文本显示操作符列表
- 总结
- 颜色
- 注意事项
- 216 种颜色的选择原因
- 当今屏幕颜色的发展
- 总结
- 字体
- 字体类型
- Base14 字体
- Type1 字体
- TrueType 字体
- CID 字体
- 总结
- 编码
- 单字节编码(Singlebyte Encodings):
- 多字节编码(Multibyte Encodings):
- 函数(Functions):
- API参考
- 基本函数
- HPDF_New() 和 HPDF_NewEx()
- HPDF_Free()
- HPDF_NewDoc()
- HPDF_FreeDoc() 和 HPDF_FreeDocAll()
- HPDF_SaveToFile()
- HPDF_SaveToStream()
- HPDF_GetStreamSize()
- 总结
- 基本函数
- HPDF_ReadFromStream()
- HPDF_ResetStream()
- HPDF_HasDoc()
- HPDF_SetErrorHandler()
- HPDF_GetError()
- HPDF_ResetError()
- HPDF_SetPagesConfiguration()
- HPDF_SetPageLayout()
- 总结
- 页面布局与模式
- HPDF_GetPageLayout()
- HPDF_SetPageMode()
- HPDF_GetPageMode()
- HPDF_SetOpenAction()
- HPDF_GetCurrentPage()
- 页面操作
- HPDF_AddPage()
- HPDF_InsertPage()
- HPDF_AddPageLabel()
- 字体处理
- HPDF_GetFont()
- 总结
- 字体加载函数
- HPDF_LoadType1FontFromFile()
- HPDF_LoadTTFontFromFile()
- HPDF_LoadTTFontFromFile2()
- HPDF_UseJPFonts()
- HPDF_UseKRFonts()
- HPDF_UseCNSFonts()
- 总结
- 字体启用函数
- HPDF_UseCNTFonts()
- HPDF_GetEncoder()
- HPDF_GetCurrentEncoder()
- HPDF_SetCurrentEncoder()
- 编码处理函数
- HPDF_UseJPEncodings()
- HPDF_UseKREncodings()
- HPDF_UseCNSEncodings()
- HPDF_UseCNTEncodings()
- HPDF_UseUTFEncodings()
- 总结
- 其他函数
- HPDF_CreateOutline()
- HPDF_LoadPngImageFromFile()
- HPDF_LoadPngImageFromFile2()
- HPDF_LoadRawImageFromFile()
- HPDF_LoadRawImageFromMem()
- HPDF_LoadPngImageFromMem()
- 总结
- 其他函数
- HPDF_LoadJpegImageFromMem()
- HPDF_LoadJpegImageFromFile()
- HPDF_SetInfoAttr()
- HPDF_GetInfoAttr()
- HPDF_SetInfoDateAttr()
- HPDF_SetPassword()
- HPDF_SetPermission()
- HPDF_SetEncryptionMode()
- HPDF_SetCompressionMode()
- 总结
- 例子
- 总结
- 编程资源
- 字体资源
- 总结
- 字体资源
- 总结
安装
LibHaru 是一个用于生成 PDF 文件的库,可以在多种操作系统上进行安装。以下是对不同操作系统上安装 LibHaru 的方法的总结:
Linux/UNIX:
- 解压缩下载的 LibHaru 包:
tar -xvzf libharu-X.X.X.tar.gz - 创建构建目录并进入:
mkdir build cd build - 使用 CMake 生成构建文件:
cmake ../libharu-X.X.X - 清理、构建库并安装到默认路径(通常是
/usr/local/include和/usr/local/lib目录):make clean make sudo make install
macOS:
使用 Homebrew 包管理器安装 LibHaru:
brew install libharu
Windows (非 Cygwin/MSYS):
LibHaru 使用 CMake 构建系统。可以通过以下方式安装:
使用 VCPKG 依赖管理器:
- 克隆 VCPKG 仓库:
git clone https://github.com/Microsoft/vcpkg.git - 进入 VCPKG 目录并初始化:
cd vcpkg ./bootstrap-vcpkg.sh - 集成 VCPKG 到当前开发环境:
./vcpkg integrate install - 安装 LibHaru:
./vcpkg install libharu
注意:
- VCPKG 中的 LibHaru 端口由 Microsoft 团队成员和社区贡献者保持最新。如果发现版本过时,可以在 VCPKG 仓库中创建 issue 或 pull request。
Cygwin/MSYS:
对于 Cygwin/MSYS 环境,可以参照 Linux/UNIX 的通用方法进行安装。
通过这些步骤,用户可以在不同操作系统上安装 LibHaru,进而在项目中生成和操作 PDF 文件。
使用
在LibHaru库中,创建和操作PDF文档的基本流程如下:
-
初始化文档对象:
使用HPDF_New()或HPDF_NewEx()创建一个HPDF_Doc类型的“文档对象”。如果需要自定义内存管理,则使用HPDF_NewEx()。这些函数返回的句柄将用于后续步骤。 -
设置错误处理:
可以在创建文档对象后指定一个用户定义的错误处理函数(这里称为“error_handler”)。使用setjmp()进行异常处理。 -
设置文档属性:
根据需要设置压缩模式、加密、页面模式和密码。 -
创建新页面:
调用HPDF_AddPage()向文档添加一个新页面。返回的页面句柄将用于后续的页面操作。 -
插入页面:
如果要在现有页面前插入新页面,可调用HPDF_InsertPage()。 -
设置页面对象:
根据需要设置页面对象的属性,例如页面大小和方向。 -
页面描述:
执行绘图操作,将文本放置在页面上。具体细节请参考“图形”章节。 -
保存文档:
使用HPDF_SaveToFile()将文档保存到文件,或使用HPDF_SaveToStream()将文档保存到临时流。通过调用HPDF_ReadFromStream()可以获取保存的数据,并可输出到标准输出。 -
创建下一个文档:
如果需要创建另一个文档,调用HPDF_NewDoc()。这个函数会在撤销当前文档后创建一个新文档。 -
最终化和清理:
所有处理完成后,调用HPDF_Free()释放文档对象所占用的所有资源。
以下是使用LibHaru创建PDF文档的示例代码的总结:
#include "hpdf.h"
// 创建PDF文档对象
HPDF_Doc pdf = HPDF_New(error_handler, NULL);
if (!pdf) {
printf("ERROR: cannot create pdf object.\n");
return 1;
}
// 异常处理
if (setjmp(env)) {
HPDF_Free(pdf);
return 1;
}
// 设置文档属性,如压缩、加密、页面模式和密码
HPDF_SetCompressionMode(pdf, HPDF_COMP_ALL);
HPDF_SetPageMode(pdf, HPDF_PAGE_MODE_USE_OUTLINE);
HPDF_SetPassword(pdf, "owner", "user");
// 创建和插入页面
HPDF_Page page_1 = HPDF_AddPage(pdf);
// HPDF_Page page_0 = HPDF_InsertPage(pdf, page_1); // 如果需要在特定页面前插入页面
// 设置页面属性,如大小和方向
HPDF_Page_SetSize(page_1, HPDF_PAGE_SIZE_B5, HPDF_PAGE_LANDSCAPE);
// 在页面上执行绘图操作和放置文本
// 保存文档到文件或流
HPDF_SaveToFile(pdf, "test.pdf");
// 或者保存到流并输出
HPDF_SaveToStream(pdf);
// ...(省略流操作代码)
// 如果需要,创建新的文档
// HPDF_NewDoc(pdf);
// 清理并释放资源
HPDF_Free(pdf);
这个流程提供了使用LibHaru库创建PDF文档的完整步骤,从初始化文档对象到最终的清理工作。
错误处理
函数类型
在Haru中,根据出错时的返回值,有三种类型的函数:
- 返回 HPDF_STATUS 的函数:出错时返回错误代码。
- 返回对象句柄的函数:出错时返回 NULL。
- 返回其他值的函数:出错时返回初始值。
错误处理
当发生错误时,首先返回函数的返回值,然后在文档对象中存储一个错误代码,最后(如果定义了)调用用户自定义的错误处理函数。
HPDF_GetError()用于返回错误代码。但如果函数的第一个参数无效,则错误代码不会设置(因此无法检索)。- 一些函数还设置了详细的错误代码,
HPDF_GetErrorDetail()用于返回详细错误代码。可以使用strerror()或平台等价物来了解失败的底层系统调用。 - 注意:一旦设置了错误代码,某些I/O处理函数将被阻塞。因此,必须调用
HPDF_ResetError()来恢复程序。
用户自定义错误处理函数
可以定义一个在发生错误时调用的用户自定义错误处理函数,其定义如下:
typedef void (*HPDF_Error_Handler) (HPDF_STATUS error_no, HPDF_STATUS detail_no, void *user_data);
在Windows环境中,如果将Haru构建为共享库,错误处理函数的定义需要使用 __stdcall 调用约定。
使用用户自定义错误处理函数
可以通过使用错误处理函数有效地进行错误处理:
C语言中的错误处理
C语言不支持直接的异常处理,但通过使用 setjmp / longjmp 来模拟异常处理,错误处理变得简单。
void error_handler(HPDF_STATUS error_no, HPDF_STATUS detail_no, void *user_data) {
printf("ERROR: error_no=%04X, detail_no=%d\n", (unsigned int)error_no, (int)detail_no);
longjmp(env, 1); // 发生错误时调用 longjmp()
}
int main() {
HPDF_Doc pdf;
pdf = HPDF_New(error_handler, NULL); // 设置错误处理函数
if (!pdf) {
printf("error: cannot create PdfDoc object\n");
return 1;
}
if (setjmp(env)) {
HPDF_Free(pdf);
return 1;
}
// 执行页面描述过程(不需要检查函数返回代码)
HPDF_SaveToFile(pdf, fname);
HPDF_Free(pdf);
return 0;
}
C++中的错误处理
C++直接支持异常处理。在发生错误时抛出异常,错误处理变得简单。
void error_handler(HPDF_STATUS error_no, HPDF_STATUS detail_no, void *user_data) {
printf("ERROR: error_no=%04X, detail_no=%d\n", (unsigned int)error_no, (int)detail_no);
throw std::exception(); // 发生错误时抛出异常
}
int main() {
HPDF_Doc pdf = HPDF_New(error_handler, NULL); // 设置错误处理函数
if (!pdf) {
printf("error: cannot create PdfDoc object\n");
return 1;
}
try {
// 执行页面描述过程(不需要检查函数返回代码)
HPDF_SaveToFile(pdf, fname);
} catch (...) {
HPDF_Free(pdf);
return 1;
}
HPDF_Free(pdf);
return 0;
}
其他编程语言
对于支持异常处理的语言,可以以类似的方式处理错误。对于不支持异常处理的语言,需要在调用函数后检查返回代码。在 “if” 目录下有Ruby、Delphi和C#的包装程序示例。可以参考它们的源代码。
错误代码列表
以下是 LibHaru 库中定义的错误代码及其描述的翻译和总结:
- HPDF_ARRAY_COUNT_ERR (0x1001):内部错误。数据一致性丢失。
- HPDF_ARRAY_ITEM_NOT_FOUND (0x1002):内部错误。数据一致性丢失。
- HPDF_ARRAY_ITEM_UNEXPECTED_TYPE (0x1003):内部错误。数据一致性丢失。
- HPDF_BINARY_LENGTH_ERR (0x1004):数据长度大于
HPDF_LIMIT_MAX_STRING_LEN。 - HPDF_CANNOT_GET_PALLET (0x1005):无法从PNG图像中获取调色板数据。
- HPDF_DICT_COUNT_ERR (0x1007):字典元素大于
HPDF_LIMIT_MAX_DICT_ELEMENT。 - HPDF_DOC_ENCRYPTDICT_NOT_FOUND (0x100B):在设置密码之前调用了
HPDF_SetEncryptMode()或HPDF_SetPermission()。 - HPDF_ENCRYPT_INVALID_PASSWORD (0x1011):尝试将所有者密码设置为 NULL 或所有者和用户密码相同。
- HPDF_EXCEED_GSTATE_LIMIT (0x1014):栈深度大于
HPDF_LIMIT_MAX_GSTATE。 - HPDF_FAILD_TO_ALLOC_MEM (0x1015):内存分配失败。
- HPDF_FILE_IO_ERROR (0x1016):文件处理失败(已设置详细代码)。
- HPDF_INVALID_AFM_HEADER (0x101B):无法识别 afm 文件的头部。
- HPDF_INVALID_ANNOTATION (0x101C):指定的注释句柄无效。
- HPDF_INVALID_COLOR_SPACE (0x1020):加载原始图像时颜色空间参数无效,或当前颜色空间下调用的函数无效。
- HPDF_INVALID_COMPRESSION_MODE (0x1021):调用
HPDF_SetCommpressionMode()时设置了无效值。 - HPDF_INVALID_DOCUMENT (0x1025):设置了无效的文档句柄。
- HPDF_INVALID_ENCODER (0x1027):设置了无效的编码器句柄。
- HPDF_INVALID_FONTDEF_DATA (0x102D):设置了无效的字体句柄或不支持的字体格式。
- HPDF_INVALID_IMAGE (0x1030):不支持的图像格式。
- HPDF_INVALID_PAGE (0x1037):指定了无效的页面句柄。
- HPDF_INVALID_PARAMETER (0x1039):设置了无效的值。
- HPDF_INVALID_PNG_IMAGE (0x103B):无效的PNG图像格式。
- HPDF_INVALID_TTC_FILE (0x103F):无效的.TTC文件格式。
- HPDF_LIBPNG_ERROR (0x1043):加载图像时PNGLIB返回了错误。
- HPDF_PAGE_CANNOT_FIND_OBJECT (0x104A):内部错误,数据一致性丢失。
- HPDF_PAGE_FONT_NOT_FOUND (0x104E):未设置当前字体。
- HPDF_PAGE_INVALID_FONT (0x104F):指定了无效的字体句柄。
- HPDF_STREAM_EOF (0x1058):检测到意外的 EOF 标记。
- HPDF_TTF_CANNOT_EMBEDDING_FONT (0x105D):由于许可限制,无法嵌入字体。
- HPDF_UNSUPPORTED_FUNC (0x1062):库未配置使用 PNGLIB 或内部错误,数据一致性丢失。
- HPDF_ZLIB_ERROR (0x1066):执行 ZLIB 函数时出错。
总结
LibHaru 定义了一系列错误代码来指示可能遇到的各种错误情况。这些错误代码覆盖了从内存分配问题、文件I/O错误、无效的参数设置到不支持的功能或格式等。了解这些错误代码及其含义对于调试和解决使用 LibHaru 库时遇到的问题至关重要。如果遇到未定义的错误代码,可能需要查阅库的文档或源代码以获取更多信息。
图像
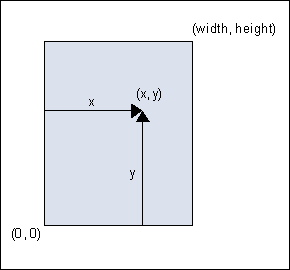
PDF默认的坐标系如下图所示,左下角坐标为(0,0),右上角坐标为(width,height),默认分辨率为72dpi。
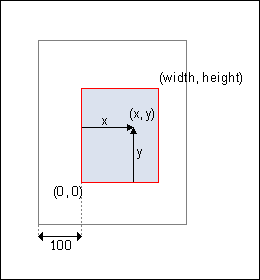
应用程序可以通过调用 HPDF_Page_Concat() 来更改坐标系。例如,如果应用程序在默认状态下调用 HPDF_Page_Concat (page, 0.5, 0, 0, 0.5, 100, 100),则上图所示的坐标系将转换为下图所示的新坐标系。
图形模式
在 libHaru 中,每个页面对象都维护一个名为“图形模式”的标志。图形模式对应于 PDF 规范的图形对象。
通过调用特定的函数来改变图形模式,可以调用的函数由图形模式的值决定。
下图显示了图形模式的关系。
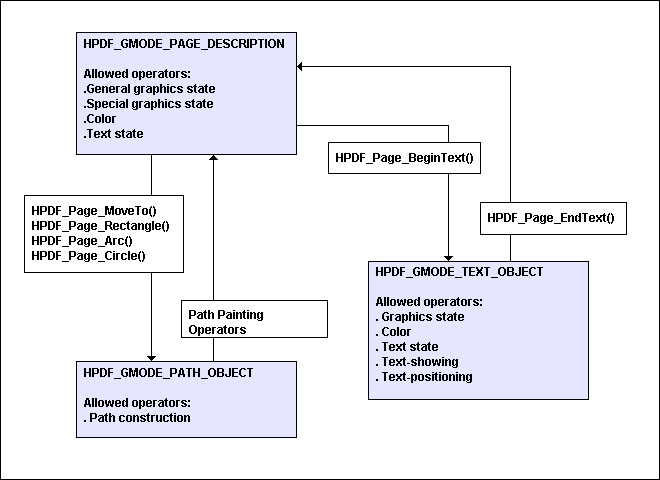
路径绘画
路径绘制
路径由直线段和曲线段组成,用于定义形状和区域。
绘制矢量图形的步骤如下:
- 使用“图形状态操作符”或“颜色操作符”设置图形状态(如线条宽度、虚线模式、颜色等)。
- 使用
HPDF_Page_MoveTo()、HPDF_Page_Rectangle()、HPDF_Page_Arc()或HPDF_Page_Circle()等函数开始新的路径。 - 使用“路径构造操作符”追加到路径。
- 使用“路径绘制操作符”描边或填充路径。
图形状态操作符列表
HPDF_Page_Concat():矩阵变换。HPDF_Page_SetDash():设置虚线模式。HPDF_Page_SetFlat():设置平面度,影响线帽和线连接的显示。HPDF_Page_SetLineCap():设置线帽样式。HPDF_Page_SetLineJoin():设置线连接样式。HPDF_Page_SetLineWidth():设置线条宽度。HPDF_Page_SetMiterLimit():设置斜接限制。
颜色操作符列表
HPDF_Page_SetCMYKFill():设置CMYK填充颜色。HPDF_Page_SetCMYKStroke():设置CMYK描边颜色。HPDF_Page_SetGrayFill():设置灰度填充颜色。HPDF_Page_SetGrayStroke():设置灰度描边颜色。HPDF_Page_SetRGBFill():设置RGB填充颜色。HPDF_Page_SetRGBStroke():设置RGB描边颜色。
路径构造操作符列表
HPDF_Page_Arc():绘制圆弧。HPDF_Page_Circle():绘制圆形。HPDF_Page_CurveTo():绘制三次贝塞尔曲线。HPDF_Page_CurveTo2():绘制二次贝塞尔曲线。HPDF_Page_CurveTo3():绘制三次贝塞尔曲线的另一种形式。HPDF_Page_LineTo():绘制直线。HPDF_Page_MoveTo():移动到新位置。HPDF_Page_Rectangle():绘制矩形。
路径绘制操作符列表
HPDF_Page_ClosePathFillStroke():关闭路径并填充描边。HPDF_Page_ClosePathEofillStroke():关闭路径并使用EOF填充并描边。HPDF_Page_ClosePathStroke():关闭路径并描边。HPDF_Page_Eofill():使用EOF(非零宽度)填充。HPDF_Page_EofillStroke():使用EOF填充并描边。HPDF_Page_EndPath():结束路径。HPDF_Page_Fill():填充路径。HPDF_Page_FillStroke():填充并描边路径。HPDF_Page_Stroke():描边路径。
总结
在LibHaru中,绘制矢量图形涉及到设置图形状态、构造路径、以及对路径进行填充或描边的操作。通过一系列操作符,开发者可以精确控制图形的外观,包括线条样式、颜色和形状。路径构造操作符允许开发者定义复杂的几何形状,而路径绘制操作符则用于完成图形的绘制,提供灵活的矢量图形绘制功能。这些操作符的组合使用,使得LibHaru能够有效地创建和渲染PDF文档中的图形元素。
文本显示
文本的绘制步骤如下:
- 调用
HPDF_Page_BeginText()开始绘制文本。 - 使用“文本状态操作符”或“颜色操作符”设置文本状态(如字体、填充颜色等)。在调用“文本显示操作符”之前,至少需要调用一次
HPDF_Page_SetFontAndSize()。 - 调用“文本定位操作符”设置文本位置。
- 调用“文本显示操作符”显示文本。
- 如有必要,重复步骤2到4。
- 调用
HPDF_Page_EndText()完成文本绘制。
注:下图解释了文本定位(需要更多解释)。

文本状态操作符列表
HPDF_Page_SetCharSpace():设置字符间距。HPDF_Page_SetFontAndSize():设置字体和大小。HPDF_Page_SetHorizontalScalling():设置水平缩放。HPDF_Page_SetTextLeading():设置文本行距。HPDF_Page_SetTextRenderingMode():设置文本渲染模式。HPDF_Page_SetTextRise():设置文本上升量。HPDF_Page_SetWordSpace():设置单词间距。
文本定位操作符列表
HPDF_Page_MoveTextPos():移动文本位置。HPDF_Page_MoveTextPos2():移动文本位置,指定x和y偏移。HPDF_Page_SetTextMatrix():设置文本矩阵。
文本显示操作符列表
HPDF_Page_ShowText():显示文本。HPDF_Page_ShowTextNextLine():在下一行显示文本。HPDF_Page_ShowTextNextLineEx():在下一行显示文本,允许调整x和y偏移。HPDF_Page_TextOut():在指定位置显示文本。HPDF_Page_TextRect():在指定矩形区域内显示文本。
总结
在LibHaru中,文本的绘制是一个有序的过程,涉及开始和结束文本块、设置文本状态、定位文本位置以及实际显示文本。通过文本状态操作符,可以控制文本的外观和布局,包括字体选择、大小调整、间距控制等。文本定位操作符允许在页面上精确放置文本,而文本显示操作符则用于将文本内容渲染到PDF文档中。这些功能为在PDF中创建格式化文本提供了强大的支持。
颜色
颜色使用三个实数(即带有小数点的数字)指定,格式为 R G B,每个数字定义了颜色中的红色(R)、绿色(G)和蓝色(B)成分。有效的数值范围是从 0.0 到 1.0。
下面是一个展示 216 种示例颜色及其实际表示的表格:
(此处省略了表格内容的翻译,因为内容较多,且为颜色代码的直接展示,不易翻译成文字描述。)
注意事项
- 上表包含所谓的“网络安全”颜色调色板,也称为浏览器安全调色板、Netscape 调色板、216 色调色板、Web 调色板或 6x6x6 颜色立方体。
- 它的目的是为了提供一致的颜色调色板,用于当时通常具有 256 种颜色(8位)的各种浏览器和操作系统。
216 种颜色的选择原因
- 从可能的 256 种颜色中选择 216 种颜色,是因为这允许在可以通过将颜色空间划分为代表红色、绿色和蓝色所有颜色成分可能值的六分之一的区域来实现的大多数显示器上均匀采样,因此我们得到一个有 6 个可能的红色区域、6 个绿色和 6 个蓝色的立方体,它们共同构成 6x6x6 = 216 种组合。
当今屏幕颜色的发展
- 今天,大多数屏幕以真彩色显示,使用 24 位,并使用每种红色、绿色和蓝色颜色成分的全部 256 种可能值,这给出了 256x256x256 = 16777216 种颜色。
总结
-
尽管现代显示技术可以呈现数百万种颜色,但“网络安全”颜色调色板仍然是考虑配色方案时的有用起点,特别是对于非艺术家来说。这个调色板提供了一个有限但协调的颜色范围,可以确保在不同的显示设备上保持颜色的一致性。
-
在设计网页或数字内容时,了解颜色如何在不同设备上显示非常重要。虽然我们不再局限于 216 色,但这个调色板提供了对颜色理论和配色方案构建的基本理解。
Below is a table showing 216 example colors and their real notations:
| 0.0, 0.0, 0.0 | 0.0, 0.0, 0.2 | 0.0, 0.0, 0.4 | 0.0, 0.0, 0.6 | 0.0, 0.0, 0.8 | 0.0, 0.0, 1.0 |
|---|---|---|---|---|---|
| 0.0, 0.2, 0.0 | 0.0, 0.2, 0.2 | 0.0, 0.2, 0.4 | 0.0, 0.2, 0.6 | 0.0, 0.2, 0.8 | 0.0, 0.2, 1.0 |
| 0.0, 0.4, 0.0 | 0.0, 0.4, 0.2 | 0.0, 0.4, 0.4 | 0.0, 0.4, 0.6 | 0.0, 0.4, 0.8 | 0.0, 0.4, 1.0 |
| 0.0, 0.6, 0.0 | 0.0, 0.6, 0.2 | 0.0, 0.6, 0.4 | 0.0, 0.6, 0.6 | 0.0, 0.6, 0.8 | 0.0, 0.6, 1.0 |
| 0.0, 0.8, 0.0 | 0.0, 0.8, 0.2 | 0.0, 0.8, 0.4 | 0.0, 0.8, 0.6 | 0.0, 0.8, 0.8 | 0.0, 0.8, 1.0 |
| 0.0, 1.0, 0.0 | 0.0, 1.0, 0.2 | 0.0, 1.0, 0.4 | 0.0, 1.0, 0.6 | 0.0, 1.0, 0.8 | 0.0, 1.0, 1.0 |
| 0.2, 0.0, 0.0 | 0.2, 0.0, 0.2 | 0.2, 0.0, 0.4 | 0.2, 0.0, 0.6 | 0.2, 0.0, 0.8 | 0.2, 0.0, 1.0 |
| 0.2, 0.2, 0.0 | 0.2, 0.2, 0.2 | 0.2, 0.2, 0.4 | 0.2, 0.2, 0.6 | 0.2, 0.2, 0.8 | 0.2, 0.2, 1.0 |
| 0.2, 0.4, 0.0 | 0.2, 0.4, 0.2 | 0.2, 0.4, 0.4 | 0.2, 0.4, 0.6 | 0.2, 0.4, 0.8 | 0.2, 0.4, 1.0 |
| 0.2, 0.6, 0.0 | 0.2, 0.6, 0.2 | 0.2, 0.6, 0.4 | 0.2, 0.6, 0.6 | 0.2, 0.6, 0.8 | 0.2, 0.6, 1.0 |
| 0.2, 0.8, 0.0 | 0.2, 0.8, 0.2 | 0.2, 0.8, 0.4 | 0.2, 0.8, 0.6 | 0.2, 0.8, 0.8 | 0.2, 0.8, 1.0 |
| 0.2, 1.0, 0.0 | 0.2, 1.0, 0.2 | 0.2, 1.0, 0.4 | 0.2, 1.0, 0.6 | 0.2, 1.0, 0.8 | 0.2, 1.0, 1.0 |
| 0.4, 0.0, 0.0 | 0.4, 0.0, 0.2 | 0.4, 0.0, 0.4 | 0.4, 0.0, 0.6 | 0.4, 0.0, 0.8 | 0.4, 0.0, 1.0 |
| 0.4, 0.2, 0.0 | 0.4, 0.2, 0.2 | 0.4, 0.2, 0.4 | 0.4, 0.2, 0.6 | 0.4, 0.2, 0.8 | 0.4, 0.2, 1.0 |
| 0.4, 0.4, 0.0 | 0.4, 0.4, 0.2 | 0.4, 0.4, 0.4 | 0.4, 0.4, 0.6 | 0.4, 0.4, 0.8 | 0.4, 0.4, 1.0 |
| 0.4, 0.6, 0.0 | 0.4, 0.6, 0.2 | 0.4, 0.6, 0.4 | 0.4, 0.6, 0.6 | 0.4, 0.6, 0.8 | 0.4, 0.6, 1.0 |
| 0.4, 0.8, 0.0 | 0.4, 0.8, 0.2 | 0.4, 0.8, 0.4 | 0.4, 0.8, 0.6 | 0.4, 0.8, 0.8 | 0.4, 0.8, 1.0 |
| 0.4, 1.0, 0.0 | 0.4, 1.0, 0.2 | 0.4, 1.0, 0.4 | 0.4, 1.0, 0.6 | 0.4, 1.0, 0.8 | 0.4, 1.0, 1.0 |
| 0.6, 0.0, 0.0 | 0.6, 0.0, 0.2 | 0.6, 0.0, 0.4 | 0.6, 0.0, 0.6 | 0.6, 0.0, 0.8 | 0.6, 0.0, 1.0 |
| 0.6, 0.2, 0.0 | 0.6, 0.2, 0.2 | 0.6, 0.2, 0.4 | 0.6, 0.2, 0.6 | 0.6, 0.2, 0.8 | 0.6, 0.2, 1.0 |
| 0.6, 0.4, 0.0 | 0.6, 0.4, 0.2 | 0.6, 0.4, 0.4 | 0.6, 0.4, 0.6 | 0.6, 0.4, 0.8 | 0.6, 0.4, 1.0 |
| 0.6, 0.6, 0.0 | 0.6, 0.6, 0.2 | 0.6, 0.6, 0.4 | 0.6, 0.6, 0.6 | 0.6, 0.6, 0.8 | 0.6, 0.6, 1.0 |
| 0.6, 0.8, 0.0 | 0.6, 0.8, 0.2 | 0.6, 0.8, 0.4 | 0.6, 0.8, 0.6 | 0.6, 0.8, 0.8 | 0.6, 0.8, 1.0 |
| 0.6, 1.0, 0.0 | 0.6, 1.0, 0.2 | 0.6, 1.0, 0.4 | 0.6, 1.0, 0.6 | 0.6, 1.0, 0.8 | 0.6, 1.0, 1.0 |
| 0.8, 0.0, 0.0 | 0.8, 0.0, 0.2 | 0.8, 0.0, 0.4 | 0.8, 0.0, 0.6 | 0.8, 0.0, 0.8 | 0.8, 0.0, 1.0 |
| 0.8, 0.2, 0.0 | 0.8, 0.2, 0.2 | 0.8, 0.2, 0.4 | 0.8, 0.2, 0.6 | 0.8, 0.2, 0.8 | 0.8, 0.2, 1.0 |
| 0.8, 0.4, 0.0 | 0.8, 0.4, 0.2 | 0.8, 0.4, 0.4 | 0.8, 0.4, 0.6 | 0.8, 0.4, 0.8 | 0.8, 0.4, 1.0 |
| 0.8, 0.6, 0.0 | 0.8, 0.6, 0.2 | 0.8, 0.6, 0.4 | 0.8, 0.6, 0.6 | 0.8, 0.6, 0.8 | 0.8, 0.6, 1.0 |
| 0.8, 0.8, 0.0 | 0.8, 0.8, 0.2 | 0.8, 0.8, 0.4 | 0.8, 0.8, 0.6 | 0.8, 0.8, 0.8 | 0.8, 0.8, 1.0 |
| 0.8, 1.0, 0.0 | 0.8, 1.0, 0.2 | 0.8, 1.0, 0.4 | 0.8, 1.0, 0.6 | 0.8, 1.0, 0.8 | 0.8, 1.0, 1.0 |
| 1.0, 0.0, 0.0 | 1.0, 0.0, 0.2 | 1.0, 0.0, 0.4 | 1.0, 0.0, 0.6 | 1.0, 0.0, 0.8 | 1.0, 0.0, 1.0 |
| 1.0, 0.2, 0.0 | 1.0, 0.2, 0.2 | 1.0, 0.2, 0.4 | 1.0, 0.2, 0.6 | 1.0, 0.2, 0.8 | 1.0, 0.2, 1.0 |
| 1.0, 0.4, 0.0 | 1.0, 0.4, 0.2 | 1.0, 0.4, 0.4 | 1.0, 0.4, 0.6 | 1.0, 0.4, 0.8 | 1.0, 0.4, 1.0 |
| 1.0, 0.6, 0.0 | 1.0, 0.6, 0.2 | 1.0, 0.6, 0.4 | 1.0, 0.6, 0.6 | 1.0, 0.6, 0.8 | 1.0, 0.6, 1.0 |
| 1.0, 0.8, 0.0 | 1.0, 0.8, 0.2 | 1.0, 0.8, 0.4 | 1.0, 0.8, 0.6 | 1.0, 0.8, 0.8 | 1.0, 0.8, 1.0 |
| 1.0, 1.0, 0.0 | 1.0, 1.0, 0.2 | 1.0, 1.0, 0.4 | 1.0, 1.0, 0.6 | 1.0, 1.0, 0.8 | 1.0, 1.0, 1.0 |
Note:
字体
字体类型
LibHaru 提供了几种可用的字体类型:
-
Base14 字体:PDF 的内置字体,可被所有查看器应用程序使用。使用
HPDF_GetFont()获取字体句柄。 -
Type1 字体:Adobe 开发的轮廓字体格式。使用
HPDF_LoadType1FontFromFile()加载字体。 -
TrueType 字体:广泛使用的轮廓字体格式。使用
HPDF_LoadTTFontFromFile()或HPDF_LoadTTFontFromFile2()加载字体。 -
CID 字体:Adobe 开发的多字节字符字体格式。使用
HPDF_UseCNSFonts()、HPDF_UseCNTFonts()、HPDF_UseJPFonts()或HPDF_UseKRFonts()激活字体。
Base14 字体
Base14 字体内置于 PDF 中,所有查看器应用程序都可以显示这些字体。使用 Base14 字体的 PDF 文件比其他类型的字体更小,处理速度更快,因为不需要加载外部字体。但是,Base14 字体只能显示 latin1 字符集。要使用其他字符集,应用程序必须使用其他字体。
内置的 Base14 字体包括:
- Courier
- Courier-Bold
- Courier-Oblique
- Courier-BoldOblique
- Helvetica
- Helvetica-Bold
- Helvetica-Oblique
- Helvetica-BoldOblique
- Times-Roman
- Times-Bold
- Times-Italic
- Times-BoldItalic
- Symbol
- ZapfDingbats
Type1 字体
Type1 是 Adobe 开发的轮廓字体格式。要在 Haru 中使用外部 Type1 字体,需要 AFM 文件。使用 HPDF_LoadType1FontFromFile() 并调用 HPDF_GetFont() 来加载字体。如果指定了 PFA/PFB 文件,字体的 glyf 数据将嵌入到 PDF 文件中。
TrueType 字体
LibHaru 可以使用 TrueType 字体。有两种类型的 TrueType 字体:
- 一个字体数据的 “.ttf” 格式,使用
HPDF_LoadTTFontFromFile()加载。 - 包含多个字体数据的 “.ttc” 格式,使用
HPDF_LoadTTFontFromFile2()加载,并可以选择加载的字体索引。
如果调用 HPDF_LoadTTFontFromFile() 或 HPDF_LoadTTFontFromFile2() 时将 “embedding” 参数设置为 HPDF_TRUE,则字体的子集将嵌入到 PDF 文件中。否则,只存储 marix 数据。
CID 字体
CIDFont 是 Adobe 为多字节字符开发的字体格式。LibHaru 提供了简体中文(SimSun, SimHei)、繁体中文(MingLiU)、日文(MS-Mincyo, MS-Gothic, MS-PMincyo, MS-PGothic)和韩文(Batang, Dotum, BatangChe, DotumChe)字体。在使用 CID 字体之前,需要调用相应的函数来激活它们。
总结
LibHaru 支持多种字体类型,包括内置的 Base14 字体、Type1、TrueType 和 CID 字体,以满足不同语言和字符集的需求。应用程序可以根据需要加载和使用这些字体来创建 PDF 文档。对于 CID 字体,需要先激活才能使用。通过这些功能,LibHaru 提供了灵活的字体使用选项,以支持国际化的 PDF 文档创建。
编码
LibHaru 是一个用于生成 PDF 文件的免费、跨平台的开源库。它支持多种字符编码,包括单字节和多字节字符集。以下是对 LibHaru 支持的编码的总结:
单字节编码(Singlebyte Encodings):
- StandardEncoding:PDF 默认编码。
- MacRomanEncoding:Mac OS 标准编码。
- WinAnsiEncoding:Windows 标准编码。
- FontSpecific:使用字体内置的编码。
- ISO8859-2 至 ISO8859-16:拉丁字母表 No.2 至 No.10,以及泰文 TIS 620-2569 字符集。
- CP1250 至 CP1258:Microsoft Windows 代码页,涵盖多种欧洲语言。
多字节编码(Multibyte Encodings):
- GB-EUC-H 和 GB-EUC-V:简体中文 EUC 编码,包括垂直书写版本。
- GBK-EUC-H 和 GBK-EUC-V:微软代码页 936(GBK 编码),包括垂直书写版本。
- ETen-B5-H 和 ETen-B5-V:繁体中文 ETen 扩展的 Big Five 字符集,包括垂直书写版本。
- 90ms-RKSJ-H 和 90ms-RKSJ-V:微软代码页 932,JIS X 0208 字符集,包括垂直书写版本。
- EUC-H 和 EUC-V:JIS X 0208 字符集,EUC-JP 编码,包括垂直书写版本。
- KSC-EUC-H 和 KSC-EUC-V:KS X 1001:1992 字符集,EUC-KR 编码,包括垂直书写版本。
- KSCms-UHC-H 系列:微软代码页 949,KS X 1001:1992 字符集加上额外的韩文,UHC 编码,包括不同书写方式的版本。
函数(Functions):
在使用多字节编码之前,应用程序需要调用以下函数来使相应的编码可用:
- HPDF_UseCNSEncodings():使简体中文编码可用。
- HPDF_UseCNTEncodings():使繁体中文编码可用。
- HPDF_UseJPEncodings():使日文编码可用。
- HPDF_UseKREncodings():使韩文编码可用。
LibHaru 通过这些编码支持,使得开发者能够在 PDF 文档中使用各种语言和字符集,增强了 PDF 文件的国际化和多语言能力。
API参考
基本函数
HPDF_New() 和 HPDF_NewEx()
这两个函数用于创建文档对象的实例并初始化它。
-
参数:
user_error_fn:用户定义的错误处理函数,当发生错误时调用。user_alloc_fn:用户定义的内存分配函数。如果指定 NULL,则使用 malloc()。user_free_fn:用户定义的内存释放函数。如果指定 NULL,则使用 free()。mem_pool_buf_size:如果设置非零值,内存管理将按照指定的方式进行。user_data:用户定义的 void 指针,用于错误处理。
-
返回值:成功时返回文档对象的句柄,失败时返回 NULL。
HPDF_Free()
撤销文档对象及其所有资源。
- 参数:
pdf- 文档对象的句柄。
HPDF_NewDoc()
创建一个新文档。如果 HPDF_Doc 对象已经有文档,则当前文档将被撤销。
- 参数:
pdf- 文档对象的句柄。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_FreeDoc() 和 HPDF_FreeDocAll()
撤销当前文档。
-
HPDF_FreeDoc()在需要这些资源的新文档时,保留并回收已加载的资源(如字体和编码)。 -
HPDF_FreeDocAll()撤销当前文档和所有资源。 -
参数:
pdf- 文档对象的句柄。
HPDF_SaveToFile()
将当前文档保存到文件。
-
参数:
pdf- 文档对象的句柄。file_name- 要保存的文件名。
-
返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_SaveToStream()
将当前文档保存到文档对象的临时流。
- 参数:
pdf- 文档对象的句柄。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_GetStreamSize()
获取文档的临时流的大小。
- 参数:
pdf- 文档对象的句柄。 - 返回值:成功时返回临时流的大小,否则返回 0。
总结
LibHaru 通过一系列基本函数提供了创建、管理、保存和撤销 PDF 文档的能力。这些函数涵盖了从初始化文档对象、设置错误处理函数、分配和释放内存,到保存文档到文件或流、获取流大小等操作。HPDF_New() 和 HPDF_NewEx() 提供了灵活的内存管理选项,而 HPDF_Free() 允许清理资源。HPDF_NewDoc()、HPDF_FreeDoc() 和 HPDF_FreeDocAll() 支持文档的创建和撤销。HPDF_SaveToFile() 和 HPDF_SaveToStream() 则提供了文档保存的功能。这些基本函数构成了使用 LibHaru 库操作 PDF 文档的基础。
基本函数
HPDF_ReadFromStream()
从文档的临时流中将数据复制到缓冲区 “buf”。
- 参数:
pdf(文档对象的句柄),buf(缓冲区的指针),size(缓冲区的大小)。 - 返回值:成功时返回 HPDF_OK 或 HPDF_STREAM_EOF,否则返回错误代码并调用错误处理函数。
HPDF_ResetStream()
倒带文档的临时流。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_HasDoc()
检查指定的文档句柄是否有效。
- 参数:
pdf(文档对象的句柄)。 - 返回值:如果文档句柄有效,返回 HPDF_TRUE,否则返回 HPDF_FALSE。
HPDF_SetErrorHandler()
设置用户定义的错误处理函数。
- 参数:
pdf(文档对象的句柄),user_error_fn(用户定义的错误处理函数)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_GetError()
返回指定文档对象的最后一个错误代码。
- 参数:
pdf(文档对象的句柄)。 - 返回值:返回文档对象的最后一个错误代码,如果没有错误则返回 HPDF_OK。
HPDF_ResetError()
清除错误代码,以便重新执行 I/O 处理函数。
- 参数:
pdf(文档对象的句柄)。
页面处理
HPDF_SetPagesConfiguration()
设置页面树的配置。
- 参数:
pdf(文档对象的句柄),page_per_pages(每个 “Pages” 对象可以拥有的页面数)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_SetPageLayout()
设置页面显示方式。
- 参数:
pdf(文档对象的句柄),layout(页面布局方式)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
总结
LibHaru 提供了一系列基本函数来管理 PDF 文档的流、错误处理、页面布局和配置。这些函数允许开发者读取和写入文档流、设置和获取错误处理函数、检查文档的有效性、配置页面的组织结构以及设置页面的布局。通过这些函数,LibHaru 确保了 PDF 文档的有效管理和灵活的页面处理能力。
页面布局与模式
HPDF_GetPageLayout()
返回当前页面布局设置。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回当前页面布局设置,未设置时返回 HPDF_PAGE_LAYOUT_EOF。
HPDF_SetPageMode()
设置文档的显示方式。
- 参数:
pdf(文档对象的句柄)。mode(显示模式,包括不显示大纲和缩略图、仅显示大纲、仅显示缩略图、全屏显示)。
- 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_GetPageMode()
返回当前页面模式设置。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回当前页面模式设置。
HPDF_SetOpenAction()
设置文档打开时首先显示的页面。
- 参数:
pdf(文档对象的句柄),open_action(有效的目标对象)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_GetCurrentPage()
返回当前页面对象的句柄。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回当前页面对象的句柄,否则返回 NULL。
页面操作
HPDF_AddPage()
在文档的最后添加一个新页面。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回新创建的页面对象的句柄,否则返回错误代码并调用错误处理函数。
HPDF_InsertPage()
在指定页面前插入一个新页面。
- 参数:
pdf(文档对象的句柄),target(指定页面对象的句柄)。 - 返回值:成功时返回新创建的页面对象的句柄,否则返回 NULL 并调用错误处理函数。
HPDF_AddPageLabel()
为文档添加页面标签范围。
- 参数:
pdf(文档对象的句柄)。page_num(应用此标签范围的第一页)。style(编号风格)。first_page(起始页码)。prefix(页面标签的前缀)。
- 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
字体处理
HPDF_GetFont()
获取请求的字体对象的句柄。
- 参数:
pdf(文档对象的句柄)。font_name(有效的字体名称)。encoding_name(有效的编码名称)。
- 返回值:成功时返回字体对象的句柄,否则返回 NULL 并调用错误处理函数。
总结
LibHaru 提供了一系列函数来管理 PDF 文档的页面布局、模式、页面操作和字体。这些函数允许开发者获取和设置页面布局、页面模式、定义打开操作、获取当前页面、添加新页面、插入页面、添加页面标签和获取字体对象。通过这些函数,LibHaru 确保了 PDF 文档的页面可以灵活地被创建、组织和显示,同时提供了丰富的字体支持,以满足不同语言和格式的需求。
字体加载函数
HPDF_LoadType1FontFromFile()
从外部文件加载 Type1 字体并将其注册到文档对象。
- 参数:
pdf(文档对象的句柄)。afmfilename(AFM 文件的路径)。pfmfilename(PFA/PFB 文件的路径。如果为 NULL,则字体的字形数据不会嵌入到 PDF 文件中)。
- 返回值:成功时返回字体名称,否则返回 NULL 并调用错误处理函数。
HPDF_LoadTTFontFromFile()
从外部文件加载 TrueType 字体并将其注册到文档对象。
- 参数:
pdf(文档对象的句柄)。file_name(TrueType 字体文件(.ttf)的路径)。embedding(如果设置为 HPDF_TRUE,则字体的字形数据将被嵌入,否则只包含矩阵数据在 PDF 文件中)。
- 返回值:成功时返回字体名称,否则返回 NULL 并调用错误处理函数。
HPDF_LoadTTFontFromFile2()
从 TrueType 集合文件加载 TrueType 字体并将其注册到文档对象。
- 参数:
pdf(文档对象的句柄)。file_name(TrueType 字体集合文件(.ttc)的路径)。index(要加载的字体的索引)。embedding(如果为 HPDF_TRUE,则字体的字形数据将被嵌入,否则只包含矩阵数据在 PDF 文件中)。
- 返回值:成功时返回字体名称,否则返回 NULL 并调用错误处理函数。
HPDF_UseJPFonts()
启用日文字体。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_UseKRFonts()
启用韩文字体。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_UseCNSFonts()
启用简体中文字体。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
总结
LibHaru 提供了多种函数来加载和管理不同类型和语言的字体。这些函数允许开发者在 PDF 文档中嵌入和使用 TrueType 字体、Type1 字体,以及特定于语言的 CID 字体集。通过这些函数,开发者可以根据需要加载字体,并确保文档中的文本以正确的字体样式显示。每种字体加载函数都有其特定的错误代码,以便在加载过程中出现问题时进行调试和错误处理。此外,启用特定语言的字体集合(如日文、韩文、简体中文)可以简化字体的使用和管理。
字体启用函数
HPDF_UseCNTFonts()
启用繁体中文字库。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_GetEncoder()
根据指定的编码名称获取编码器对象的句柄。
- 参数:
pdf(文档对象的句柄)。encoding_name(有效的编码名称)。
- 返回值:成功时返回编码器对象的句柄,否则返回 NULL 并调用错误处理函数。
HPDF_GetCurrentEncoder()
获取文档对象的当前编码器的句柄。
- 参数:
pdf(文档对象的句柄)。 - 返回值:返回当前编码器对象的句柄或 NULL。
HPDF_SetCurrentEncoder()
设置文档的当前编码器。
- 参数:
pdf(文档对象的句柄)。encoding_name(编码名称)。
- 返回值:成功时返回创建的大纲对象的句柄,否则返回 NULL 并调用错误处理函数。
编码处理函数
HPDF_UseJPEncodings()
启用日文编码。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_UseKREncodings()
启用韩文编码。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_UseCNSEncodings()
启用简体中文编码。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_UseCNTEncodings()
启用繁体中文编码。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_UseUTFEncodings()
启用 UTF-8 编码。
- 参数:
pdf(文档对象的句柄)。 - 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
总结
LibHaru 提供了一组函数来启用和处理不同语言的字体和编码。这些函数包括启用特定语言的字体(如繁体中文的 MingLiU 字体),获取和设置文档的编码器,以及启用特定语言的编码(如日文、韩文、简体中文和繁体中文的编码)。通过这些函数,开发者可以在 PDF 文档中使用各种语言的字体和编码,确保文本以正确的语言样式显示。启用编码的函数还允许使用 UTF-8 编码的 Unicode 文本,这为国际化的 PDF 文档创建提供了支持。这些功能使得 LibHaru 成为一个灵活的 PDF 生成库,能够满足多种语言环境的需求。
其他函数
HPDF_CreateOutline()
创建一个新的大纲对象。
- 参数:
pdf(文档对象的句柄)。parent(父大纲对象的句柄。如果为 NULL,则创建为根大纲)。title(大纲对象的标题)。encoder(应用于标题的编码对象的句柄。如果为 NULL,则使用 PDFDocEncoding)。
- 返回值:成功时返回创建的大纲对象的句柄,否则返回 NULL 并调用错误处理函数。
HPDF_LoadPngImageFromFile()
从外部 PNG 图像文件加载图像。
- 参数:
pdf(文档对象的句柄)。filename(PNG 图像文件的路径)。
- 返回值:成功时返回图像对象的句柄,否则返回 NULL 并调用错误处理函数。
HPDF_LoadPngImageFromFile2()
从外部 PNG 图像文件加载图像,与 HPDF_LoadPngImageFromFile() 不同,它不会立即加载所有数据(只加载大小和颜色属性)。主要数据在图像对象写入 PDF 之前加载,并在写入后立即删除。
- 参数:同 HPDF_LoadPngImageFromFile()。
- 返回值:同 HPDF_LoadPngImageFromFile()。
HPDF_LoadRawImageFromFile()
加载“原始”图像格式的图像。此函数在不进行任何转换的情况下加载数据,因此通常比其他函数更快。
- 参数:
pdf(文档对象的句柄)。filename(图像文件的路径)。width(图像的宽度)。height(图像的高度)。color_space(颜色空间)。
- 返回值:成功时返回图像对象的句柄,否则返回 NULL 并调用错误处理函数。
HPDF_LoadRawImageFromMem()
从缓冲区加载“原始”图像格式的图像。
- 参数:
pdf(文档对象的句柄)。buf(指向图像数据的指针)。width(图像的宽度)。height(图像的高度)。color_space(颜色空间)。bits_per_component(每个颜色分量的位数)。
- 返回值:成功时返回图像对象的句柄,否则返回 NULL 并调用错误处理函数。
HPDF_LoadPngImageFromMem()
从缓冲区加载 PNG 图像。
- 参数:
pdf(文档对象的句柄)。buf(指向图像数据的指针)。size(数据缓冲区的大小)。
- 返回值:成功时返回图像对象的句柄,否则返回 NULL 并调用错误处理函数。
总结
LibHaru 提供了一系列函数来处理 PDF 文档中的大纲和图像加载。HPDF_CreateOutline() 函数用于创建 PDF 文档中的大纲对象,支持设置父大纲和标题文本。HPDF_LoadPngImageFromFile() 和 HPDF_LoadPngImageFromFile2() 函数用于从文件加载 PNG 图像,其中后者延迟加载图像数据以节省内存。HPDF_LoadRawImageFromFile() 和 HPDF_LoadRawImageFromMem() 函数支持从文件和内存加载原始格式的图像,允许指定图像的宽度、高度和颜色空间。HPDF_LoadPngImageFromMem() 函数用于从内存中的缓冲区加载 PNG 图像。这些函数提供了灵活的图像加载选项,支持不同的图像格式和加载策略,以满足不同 PDF 文档创建需求。
其他函数
HPDF_LoadJpegImageFromMem()
从缓冲区加载 JPEG 图像。
- 参数:
pdf(文档对象的句柄)。buf(指向图像数据的指针)。size(数据缓冲区的大小)。
- 返回值:成功时返回图像对象的句柄,否则返回 NULL 并调用错误处理函数。
HPDF_LoadJpegImageFromFile()
从外部 JPEG 图像文件加载图像。
- 参数:
pdf(文档对象的句柄)。filename(JPEG 图像文件的路径)。
- 返回值:同 HPDF_LoadJpegImageFromMem()。
HPDF_SetInfoAttr()
设置文档信息字典属性的文本。
- 参数:
pdf(文档对象的句柄)。type(信息类型,如作者、创建者、标题、主题、关键词等)。value(要设置的属性文本)。
- 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_GetInfoAttr()
从信息字典获取属性值。
- 参数:同 HPDF_SetInfoAttr()。
- 返回值:成功时返回信息字典的字符串值,如果信息未设置或发生错误,则返回 NULL。
HPDF_SetInfoDateAttr()
设置信息字典中的日期时间属性。
- 参数:
pdf(文档对象的句柄)。type(日期时间属性类型,如创建日期、修改日期)。value(HPDF_Date 结构,包含日期时间的新值)。
- 返回值:成功时返回 HPDF_OK,否则返回错误代码并调用错误处理函数。
HPDF_SetPassword()
为文档设置密码。
- 参数:
pdf(文档对象的句柄)。owner_passwd(文档所有者的密码)。user_passwd(文档用户的密码)。
- 返回值:同 HPDF_SetInfoAttr()。
HPDF_SetPermission()
设置文档的权限标志。
- 参数:
pdf(文档对象的句柄)。permission(权限组合,如阅读、打印、编辑等)。
- 返回值:同 HPDF_SetInfoAttr()。
HPDF_SetEncryptionMode()
设置加密模式。
- 参数:
pdf(文档对象的句柄)。mode(加密模式,如 HPDF_ENCRYPT_R2 或 HPDF_ENCRYPT_R3)。key_len(加密密钥的字节长度)。
- 返回值:同 HPDF_SetInfoAttr()。
HPDF_SetCompressionMode()
设置压缩模式。
- 参数:
pdf(文档对象的句柄)。mode(压缩模式组合,如不压缩、压缩文本、压缩图像等)。
- 返回值:同 HPDF_SetInfoAttr()。
总结
LibHaru 提供了一系列函数来处理 JPEG 图像的加载、文档信息和加密设置。这些函数包括从内存和文件加载 JPEG 图像、设置和获取文档信息属性、设置文档的创建和修改日期、设置文档密码和权限、设置加密模式以及设置压缩模式。通过这些函数,开发者可以对 PDF 文档的安全性、性能和元数据进行精细控制,满足不同的文档创建和处理需求。
例子
这段文字描述了 LibHaru 库的一系列示例程序,它们演示了如何在不同编程语言中使用 LibHaru 来生成 PDF 文档,并展示了各种 PDF 功能。以下是每个示例程序的翻译和总结:
-
font_demo.c:一个展示 Base14 字体列表的程序。
- 提供了 C、Ruby、C# 和 Swift 语言的源代码。
- 展示了生成的 PDF 文件。
-
line_demo.c:一个展示各种线条图形的程序。
- 提供了 C、Delphi/Free Pascal、C# 和 Swift 语言的源代码。
- 展示了生成的 PDF 文件。
-
text_demo.c:一个展示不同文本显示方式的程序。
- 提供了 C 和 C# 语言的源代码。
- 展示了生成的 PDF 文件。
-
text_demo2.c:一个额外的演示程序,展示不同的文本显示方式。
- 提供了 C 和 Ruby 语言的源代码。
- 展示了生成的 PDF 文件。
-
png_demo.c, jpeg_demo.c, raw_image_demo.c:这些示例程序解释了如何加载图片。
- 提供了 C 和 C# 语言的源代码。
- 展示了生成的 PDF 文件。
-
encoding_list.c:展示了不同编码下字符列表的程序。
- 展示了生成的 PDF 文件。
-
encryption.c, permission.c:这些程序描述了如何创建加密的 PDF 文件。
- 提供了 C 和 Ruby 语言的源代码。
- 展示了生成的 PDF 文件,其中用户密码为 “user”。
-
arc_demo.c:一个展示如何使用弧线和圆形函数的程序。
- 提供了 C、Ruby 和 Swift 语言的源代码。
- 展示了生成的 PDF 文件。
-
ttfont_demo.c:展示如何加载和使用 TrueType 字体的程序。使用了 Dustin Norlander 编写的 Penguin Attack 字体。
- 提供了 C、Ruby 和 Swift 语言的源代码。
- 展示了生成的 PDF 文件。
-
text_annotation.c, link_annotation.c:这些程序描述了如何使用文本、链接和网页链接注释。
- 展示了生成的 PDF 文件。
-
outline_demo.c:展示如何使用大纲的程序。
- 提供了 C 和 C# 语言的源代码。
- 展示了生成的 PDF 文件。
-
jpfont_demo.c:展示如何创建使用日文字体的 PDF 文件的程序。
- 提供了 C、Ruby 和 C# 语言的源代码。
- 需要亚洲字体包来显示生成的 PDF 文件。
-
image_demo.c:描述了如何使用特殊函数来显示图像的程序。
- 提供了 C 和 C# 语言的源代码。
- 展示了生成的 PDF 文件。
-
character_map.c:用于创建多字节编码字符列表的程序。使用方式为 “character_map ”。
- 例如,创建韩文 KSCms-UHC-HW-H 编码的列表,使用 “./character_map KSCms-UHC-HW-H BatangChe”。
- 展示了生成的 PDF 文件。
-
grid_sheet.c:用于设计报告的程序。通过在这个网格纸上叠加页面,可以使定位变得容易。
- 提供了 C 和 Swift 语言的源代码。
- 展示了生成的 PDF 文件。
总结
LibHaru 库提供了一系列的示例程序,涵盖了从基本的字体展示、线条和形状绘制、文本注释、图像加载到加密和特殊功能的演示。这些示例程序不仅展示了 LibHaru 的功能,还提供了如何在不同编程语言中实现这些功能的方法。这些示例对于学习和使用 LibHaru 库创建 PDF 文档非常有用。
以下是对提供的编程资源链接的翻译和总结:
编程资源
-
PDF参考 (Adobe Systems Inc.)
- 链接
-
字体技术说明 (Adobe Systems Inc.)
- 链接
-
字符集和编码 (Adobe Systems Inc.)
- 链接
-
True Type字体格式 (Microsoft Corporation)
- 链接
-
Unicode字符数据库 (Unicode主页)
- 链接
-
程序员文件格式集合
- 链接
-
zlib首页
- 链接
-
libpng.org
- 链接
-
True Type字体转Postscript Type 1转换器
- 链接
-
CMake - 跨平台构建系统
- 链接
字体资源
-
Cheapskatefonts.com (“Penguin Attack” 字体由Dustin Norlander编写)
- 链接
-
“Konatu” 字体 (日文字体,由mitiya masuda编写)
- 链接
-
Ghostscript 6.0 字体
- 链接
-
Type1 KOI8-R 字体集
- 通过FTP: 链接
-
CM-Super字体包
- 链接
-
Caslon风格,ISO 8859系列字体
- 链接
总结
s.html)
-
True Type字体格式 (Microsoft Corporation)
- 链接
-
Unicode字符数据库 (Unicode主页)
- 链接
-
程序员文件格式集合
- 链接
-
zlib首页
- 链接
-
libpng.org
- 链接
-
True Type字体转Postscript Type 1转换器
- 链接
-
CMake - 跨平台构建系统
- 链接
字体资源
-
Cheapskatefonts.com (“Penguin Attack” 字体由Dustin Norlander编写)
- 链接
-
“Konatu” 字体 (日文字体,由mitiya masuda编写)
- 链接
-
Ghostscript 6.0 字体
- 链接
-
Type1 KOI8-R 字体集
- 通过FTP: 链接
-
CM-Super字体包
- 链接
-
Caslon风格,ISO 8859系列字体
- 链接
总结
这些链接提供了丰富的编程和字体资源,包括PDF和字体格式的详细参考资料、字符集和编码信息、文件格式集合、数据压缩库、图像处理库、跨平台构建工具,以及多种字体资源。这些资源对于开发者在处理PDF文件、字体转换、图像处理和其他编程任务时非常有帮助。特别是对于需要处理多种字符集和编码的国际化应用程序,这些资源提供了宝贵的信息和工具。